ゼロから作るDeep Learning 5(生成モデル編)をRで再現してみた(第十章)(2/2)
前回
はじめに
前回は単純にラベルを付与した条件付き拡散モデルの実装を行いました。 前回のモデルでは、単純にインプットにラベルを追加しただけなので効率的にラベル情報の学習ができておらず、最悪ラベル情報が無視されることがある可能性もあります。そこで、今回はモデルにラベル情報をしっかりと伝えるために「ガイダンス」と呼ばれる仕組みを取り入れます。ガイダンスには学習器ありと学習器なしの2種類ありますが、学習器ありはロジックを考える上では重要なモデルですが実用性がなく、実際使用するときには学習器なしのモデルとなるかと思います。
ここで学習器とは画像をインプットとして、その画像のラベルを推定するようなモデルを指します。つまり、拡散モデルの中にラベル推定機構を入れることでより明示的にラベルの情報をモデルに組み込みます。しかし、学習器を別建てで用意する必要があるため学習が大変です。そのため、拡散モデルにすでに含まれているU-Netの機構を用いて条件付きと条件無しの数値をそれぞれ出力し、その差分を用いて学習していく方法を取ります。この方法だとU-Netひとつだけ用意すれば良くなるため、学習器なしモデルと呼ばれています。今回はその学習器なしモデルの実装をしていきます。
STEP 10.1:条件付き拡散モデル(ガイダンス・学習器なし)の実装
ガイダンス(学習器なし)の条件付き拡散モデルでは、U-Netについて「条件無しの誤差+gamma ×(条件付きの誤差ー条件無しの誤差)」という形で誤差を学習していきます。この括弧内が条件の有無で変化する部分であり、ガンマはその違いをどの程度学習に反映させるかを決定する係数になります。つまり、インプットされたノイズを狙った画像になる方向へのノイズへとデノイズしていきます。U-Netの実装は前回と変わらないので割愛します。以下のコードはガイダンス(学習器なし)の条件付き拡散モデルの実装になります。前回との変化点についてはコメントつけています。
DiffuserGuid <- nn_module( initialize = function(num_timesteps=1000, betas_start=0.0001, beta_end=0.02, device = "cpu") { self$num_timesteps = num_timesteps self$device = device self$betas = torch_linspace(betas_start,beta_end,num_timesteps,device = device) self$alphas = 1 - self$betas self$alpha_bars = torch_cumprod(self$alphas, dim=1) }, add_noise = function(x_0,t){ MAX_T = length(self$num_timesteps) alpha_bar = self$alpha_bars[t %>% as.array()] N = alpha_bar$size(1) alpha_bar = alpha_bar$view(c(N,1,1,1)) noise = torch_randn_like(x_0,device = self$device) x_t = torch_sqrt(alpha_bar) * x_0 + torch_sqrt(1 - alpha_bar) * noise return(list(x_t,noise)) }, #gammaを追加 denoise = function(model,x,t, labels, gamma) { MAX_T = self$num_timesteps alpha = self$alphas[t %>% as.array()] alpha_bar = self$alpha_bars[t %>% as.array()] alpha_bar_prev = self$alpha_bars[(t-1) %>% as.array()] N = alpha_bar$size(1) alpha = alpha$view(c(N,1,1,1)) alpha_bar = alpha_bar$view(c(N,1,1,1)) alpha_bar_prev = alpha_bar_prev$view(c(N,1,1,1)) model$eval() with_no_grad({ #無条件と条件付きの結果を出力し、その差を使用して学習を行う。 eps_cond = model(x,t,labels) eps_uncond = model(x,t) eps = eps_uncond + gamma * (eps_cond - eps_uncond) model$train() noise = torch_randn_like(x, device = self$device) noise[t == 2] = 0 mu = (x -((1-alpha) / torch_sqrt(1-alpha_bar)) * eps) / torch_sqrt(alpha) std = torch_sqrt((1-alpha) * (1-alpha_bar_prev) / (1-alpha_bar)) return(mu + noise * std) }) }, reverse_to_img = function(x, iscolor = F) { tensor = x * 255 tensor = tensor$clamp(0,255) tensor = tensor/ 255 tensor_array = tensor %>% as.array() tensor_dim = dim(tensor_array) color_dim = ifelse(iscolor,3,1) out = list() for(i in 1:tensor_dim[1]){ tmp = array(NA,dim = c(tensor_dim[3],tensor_dim[4],1,color_dim)) tmp[,,1,1:color_dim] = tensor_array[i,1:color_dim,,] tmp[1:tensor_dim[3],,1,] = tensor_array[i,,1:tensor_dim[3],] tmp[,1:tensor_dim[4],1,] = tensor_array[i,,,1:tensor_dim[4]] out[[i]] = as.cimg(tmp) } return(out) }, #gammaを追加 make_sample = function(model, x_shape = c(20,1,28,28), labels=NA, gamma = 3){ batch_size = x_shape[1] x = torch_randn(x_shape, device = self$device) if(labels %>% as.array() %>% is.na() %>% sum() %>% as.numeric() != 0){ labels = torch_randint(1,11,batch_size,device=self$device,dtype = torch_long()) } for(i in self$num_timesteps:2){ t = torch_tensor(rep(i,batch_size), device = self$device, dtype = torch_long()) x = self$denoise(model, x, t, labels, gamma) #gammaを追加 } return(list(x,labels)) } )
STEP 10.2:条件付き拡散モデル(ガイダンス・学習器なし)の学習&結果
では、実際に学習していきましょう。Rコードは以下の通りです。 特に、ガイダンス(学習器なし)のモデルでは、1つのU-Netで条件付きと条件無しの算出を行っていますので、両方のパターンで学習する必要があります。そのため、学習するときに10%の確率で条件無しのパターンを学習するように設定しています。これで、1つのU-Netで条件付きと条件無しの両方のパターンを学習することができます。他の部分は前回と変わりません。
img_size = 28 batch_size = 128 num_timesteps = 1000 epochs = 100 lr = 10^-3 device = ifelse(cuda_is_available(),"cuda","cpu") ds <- mnist_dataset( root = "./data", train = TRUE, # default download = TRUE, transform = function(x) { y = x %>% transform_to_tensor() } ) dl <- dataloader(ds, batch_size = batch_size, shuffle = TRUE) diffuser = DiffuserGuid(num_timesteps,device = device) model = UNetCond(num_labels=10) optimizer = optim_adam(model$parameters, lr=lr) losses = c() for(epoch in 1:epochs){ loss_sum = 0.0 cnt = 0 coro::loop(for(img in dl){ optimizer$zero_grad() x = img$x y = img$y shape = x$shape t = torch_randint(1, num_timesteps,shape[1],device = device) #確率10%で条件なしモデルを学習 if(runif(1)<0.1){ y = NA } x_noisy = diffuser$add_noise(x,t) noise_pred = model(x_noisy[[1]],t, y) loss = nnf_mse_loss(x_noisy[[2]],noise_pred,reduction = "sum") loss$backward() optimizer$step() loss_sum = loss_sum + loss$item() cnt = cnt + 1 }) loss_avg = loss_sum / cnt losses = c(losses, loss_avg) cat("Epoch: ",epoch,"| Loss: ", loss_avg) }

回したまま放置していたので、90エポックくらい回してしまいましたが、30~40エポックくらいで十分かと思います。 問題なく損失関数の値が減少していっていることがわかるかと思います。
では、最後に学習したモデルから生成した画像についてみていきましょう。 ちゃんとラベル通りに画像が生成されていることがわかるかと思います。 今回はエポック数も多かったためか、かなり鮮明に狙った数字の画像が得られています。
tmp = diffuser$make_sample(model = model, x_shape = c(10,1,28,28),gamma = 3) gen_img = diffuser$reverse_to_img(tmp[[1]]) par(mfrow=c(2,5)) par(oma = c(1, 1, 1, 1)) for(i in 1:10){ plot(gen_img[[i]] %>% mirror(axis = "x") %>% rotate_xy(-90,14,14), axes = FALSE, main = paste("label =",(tmp[[2]][i]-1) %>% as.numeric())) }

まとめ
これで一旦やりたかった拡散モデルの実装はすべて完了しました。 今回のシリーズはRを使用した実装をメインにしていましたが、時間が許せばその数理面についてもしっかり追えるような記事を書くかもしれません。この記事では、実装における雰囲気を感じ取ってもらうことができたならばうれしいです。知りたいことやりたいことは無限にあるので、是非こういう記事を書いてほしいなどあればコメントいただけますと幸いです(本当に記事を書くかどうかは検討させていただきますが・・・)。
ゼロから作るDeep Learning 5(生成モデル編)をRで再現してみた(第十章)(1/2)
前回
はじめに
前回はついに拡散モデルを実装して結果を確認しました。 VAEと比べて拡散モデルから生成した画像のほうがより鮮明でしたが、まだ不十分な点があります。 具体的には、前回までの拡散モデルでは生成される画像は完全にランダムで、自分が狙った画像を生成することができません。 そのため、今回はどのような画像を生成したいかについてもインプットして、狙った画像の生成を目的とした条件付きの拡散モデルを実装していきます。
STEP 10.1:条件付き拡散モデルのU-Net(デコーダー)の実装
すでに無条件の拡散モデルは前回実装したので、条件付き拡散モデルを実装するのはそこまで手間はかかりません。 まずはデコーダーであるU-Netのコードから手を加えていきましょう。条件付きを考えたいので、インプットされていた画像のラベル情報もデノイズする際に加えていきます。 Rコードは以下の通りです。追加した部分にコメントつけていますが、ここだけの追加でOKです。無条件のとき(ラベルがない場合)も出力できるようにIF文で条件付きかどうか判定しています。 IF文の条件が少し読みにくいですが、ただラベルの有無を確認しているだけになります。テンソルの扱いが少し慣れていないこともあり、少し冗長な形になっています。。
UNetCond <- nn_module( initialize = function(in_dim=1, time_embed_dim = 100, num_labels=NA) { self$time_embed_dim = time_embed_dim self$down1 = ConvBlock(in_dim,64,time_embed_dim) self$down2 = ConvBlock(64,128,time_embed_dim) self$bot1 = ConvBlock(128,256,time_embed_dim) self$up2 = ConvBlock(128+256,128,time_embed_dim) self$up1 = ConvBlock(128+64,64,time_embed_dim) self$out = nn_conv2d(64,in_dim, 1) self$maxpool = nn_max_pool2d(2) self$upsample = nn_upsample(scale_factor = 2, mode = "bilinear") if(!is.na(num_labels)){ self$label_emb = nn_embedding(num_labels, time_embed_dim) } }, forward = function(x, timesteps, labels = NA) { v = pos_encoding(timesteps, self$time_embed_dim, x$device) #この部分がラベル情報を埋め込むためのコード(前回からの追加部分) if(labels %>% as.array() %>% is.na() %>% sum() %>% as.numeric() == 0){ v = v + self$label_emb(labels) } x1 = self$down1(x,v) x = self$maxpool(x1) x2 = self$down2(x,v) x = self$maxpool(x2) x = self$bot1(x,v) x = self$upsample(x) x = torch_cat(c(x,x2),dim = 2) x = self$up2(x,v) x = self$upsample(x) x = torch_cat(c(x,x1), dim = 2) x = self$up1(x,v) x = self$out(x) return(x) } )
STEP 10.2:条件付き拡散モデルの実装
次に最終段階の条件付き拡散モデルの実装に移ります。 Rコードは以下の通りで、追加や更新した部分にはコメント付けています。 特にmake_sample関数ではラベルの乱数を発生させていますが、1~10の整数を発生させています。 今回使用しているMNISTの数字は0~9ですが、内部で計算される際にそれぞれのラベルのインデックスが1から配番されるので、 数字が0の画像のインデックスは1となっているため、このように1つズレたようなコーディングとなっています。
DiffuserCond <- nn_module( initialize = function(num_timesteps=1000, betas_start=0.0001, beta_end=0.02, device = "cpu") { self$num_timesteps = num_timesteps self$device = device self$betas = torch_linspace(betas_start,beta_end,num_timesteps,device = device) self$alphas = 1 - self$betas self$alpha_bars = torch_cumprod(self$alphas, dim=1) }, add_noise = function(x_0,t){ MAX_T = length(self$num_timesteps) alpha_bar = self$alpha_bars[t %>% as.array()] N = alpha_bar$size(1) alpha_bar = alpha_bar$view(c(N,1,1,1)) noise = torch_randn_like(x_0,device = self$device) x_t = torch_sqrt(alpha_bar) * x_0 + torch_sqrt(1 - alpha_bar) * noise return(list(x_t,noise)) }, denoise = function(model,x,t, labels) { MAX_T = self$num_timesteps alpha = self$alphas[t %>% as.array()] alpha_bar = self$alpha_bars[t %>% as.array()] alpha_bar_prev = self$alpha_bars[(t-1) %>% as.array()] N = alpha_bar$size(1) alpha = alpha$view(c(N,1,1,1)) alpha_bar = alpha_bar$view(c(N,1,1,1)) alpha_bar_prev = alpha_bar_prev$view(c(N,1,1,1)) model$eval() with_no_grad({ eps = model(x,t,labels) #ラベルもインプット model$train() noise = torch_randn_like(x, device = self$device) noise[t == 2] = 0 mu = (x -((1-alpha) / torch_sqrt(1-alpha_bar)) * eps) / torch_sqrt(alpha) std = torch_sqrt((1-alpha) * (1-alpha_bar_prev) / (1-alpha_bar)) return(mu + noise * std) }) }, reverse_to_img = function(x, iscolor = F) { tensor = x * 255 tensor = tensor$clamp(0,255) tensor = tensor/ 255 tensor_array = tensor %>% as.array() tensor_dim = dim(tensor_array) color_dim = ifelse(iscolor,3,1) out = list() for(i in 1:tensor_dim[1]){ tmp = array(NA,dim = c(tensor_dim[3],tensor_dim[4],1,color_dim)) tmp[,,1,1:color_dim] = tensor_array[i,1:color_dim,,] tmp[1:tensor_dim[3],,1,] = tensor_array[i,,1:tensor_dim[3],] tmp[,1:tensor_dim[4],1,] = tensor_array[i,,,1:tensor_dim[4]] out[[i]] = as.cimg(tmp) } return(out) }, #ラベルをインプットする。 make_sample = function(model, x_shape = c(20,1,28,28), labels=NA){ batch_size = x_shape[1] x = torch_randn(x_shape, device = self$device) #ラベルの乱数を発生させる。 if(labels %>% as.array() %>% is.na() %>% sum() %>% as.numeric() != 0){ labels = torch_randint(1,10,batch_size,device=self$device,dtype = torch_long()) } for(i in self$num_timesteps:2){ t = torch_tensor(rep(i,batch_size), device = self$device, dtype = torch_long()) x = self$denoise(model, x, t, labels) } #ラベルも一緒に返すように更新 return(list(x,labels)) } )
STEP 10.3:条件付き拡散モデルの学習&結果
では、上記で実装した条件付き拡散モデルを実際に学習して結果を確認してみましょう。 学習のためのRコードは以下の通りです。今回追加した部分にはコメント付けましたが、基本的にはラベルを追加したことを記載しています。
library(torchvision) img_size = 28 batch_size = 128 num_timesteps = 1000 epochs = 100 lr = 10^-3 device = ifelse(cuda_is_available(),"cuda","cpu") ds <- mnist_dataset( root = "./data", train = TRUE, # default download = TRUE, transform = function(x) { y = x %>% transform_to_tensor() } ) dl <- dataloader(ds, batch_size = batch_size, shuffle = TRUE) diffuser = DiffuserCond(num_timesteps,device = device) model = UNetCond(num_labels=10) #ラベルの種類数をインプット optimizer = optim_adam(model$parameters, lr=lr) losses = c() for(epoch in 1:epochs){ loss_sum = 0.0 cnt = 0 coro::loop(for(img in dl){ optimizer$zero_grad() x = img$x y = img$y #今回はラベルも必要 shape = x$shape t = torch_randint(1, num_timesteps,shape[1],device = device) x_noisy = diffuser$add_noise(x,t) noise_pred = model(x_noisy[[1]],t, y) #インプットにラベルを追加 loss = nnf_mse_loss(x_noisy[[2]],noise_pred,reduction = "sum") loss$backward() optimizer$step() loss_sum = loss_sum + loss$item() cnt = cnt + 1 }) loss_avg = loss_sum / cnt losses = c(losses, loss_avg) cat("Epoch: ",epoch,"| Loss: ", loss_avg) }
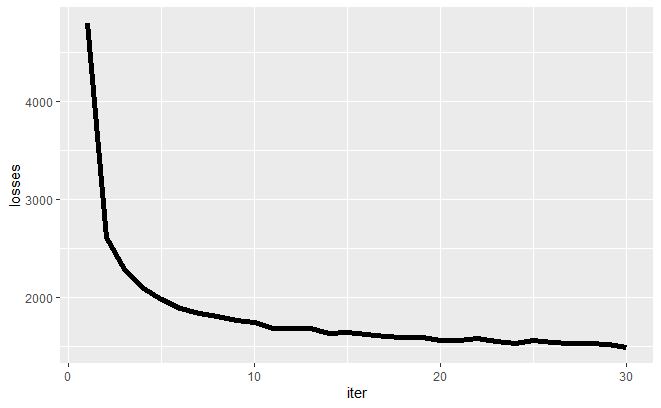
今回はエポック数を30程度で止めておきました。損失関数の推移を見る限りいい感じに学習はできてそうです。 次にちゃんとインプットしたラベル情報に沿った画像が生成されているかを確認してみましょう。以下のRコードで結果を図示できます。
tmp = diffuser$make_sample(model = model, x_shape = c(10,1,28,28)) gen_img = diffuser$reverse_to_img(tmp[[1]]) par(mfrow=c(2,5)) par(oma = c(1, 1, 1, 1)) for(i in 1:10){ plot(gen_img[[i]] %>% mirror(axis = "x") %>% rotate_xy(-90,14,14), axes = FALSE, main = paste("label =",(tmp[[2]][i]-1) %>% as.numeric())) }

ラベルと画像の内容がほぼ一致していることがわかるかと思います。 このようにラベル情報を付与するだけで狙った画像を得ることができるモデルを作成することができました。
まとめ
今回は条件付き拡散モデルの実装を行いました。まだまだ改良点は多いものの、これも立派な生成モデルと言えるかと思います。 次回は同じく条件付き拡散モデルではあるのですが、その学習方法をより洗練するための「ガイダンス」について触れ、実装していきたいと思います。
次回
ゼロから作るDeep Learning 5(生成モデル編)をRで再現してみた(第八章・第九章)
前回
はじめに
前回はVAEを実装してMNISTの数字の画像の生成をしてみました。私の手元で学習したVAEだと少しボヤっとした画像でしたが、数字であることはわかる程度の精度で生成できました。 今回は拡散モデルを実装しておなじように画像の生成を行います。参考書の第八章は拡散モデルの理論についてわかりやすく説明しています。今回のメインの目的は拡散モデルのRコードの実装であり、拡散モデル自体の理論の説明ではありません。 そのため、第八章は大幅に割愛したいと思います。その第八章の結論部分と第九章の実装部分を参照しながら、Rコードを作成していきます。
Rとpythonでは画像の扱い方が異なったりインデックスが0開始と1開始で異なったりと、元のpythonコードと異なる点がいくつかあります。 ちなみに、今回お見せする結果はCPUで推定したモデルですが、私の環境でGPUを使用するとsession aborted fatal errorとなり強制終了となってしまいました。 また、お見せしているコードのdevice部分をcpuからcudaに変えるとUNet部分でCPUとGPUが混ざってしまうため、session aborted fatal errorとならない、かつCPUとGPUが混ざらないように色々と試行錯誤してみたのですが、まだうまくいっていません。 ここら辺がうまくいったら本稿のコードを更新したいと思っていますが、ご覧になった方で直すべきポイントがわかる方がいらっしゃいましたらコメントいただけますと幸いです。。
STEP 9.1:拡散モデルについて
前回のVAEでは、元の画像を潜在変数へと変換するエンコーダーと、潜在変数を元の画像に戻すデコーダーの2種類のモデルがくっ付いたモデルとなっていました。 そのため、潜在変数を適当に生成してデコーダーにインプットすれば、学習に使用した画像の特徴を持つ画像が生成できます。
一方、拡散モデルは元の画像にノイズを徐々に加えていき、最終的にはノイズしかない状態までもっていきます(VAEで言うとエンコーダー部分に近い)。 そして、そのノイズが含まれた画像から徐々にノイズを取り除くことで元の画像に戻していき、最終的にノイズを消して画像を取り出すというモデルです(こちらはデコーダー部分)。 そのため、モデルを学習した後、ノイズ(乱数)を発生させて拡散モデルのデコーダーにインプットすれば、徐々にそのノイズから画像が生成されていく、ということになります。
ちなみに、この技術を活用したモデルにStable Diffusionがありますが、Stable Diffusionの大枠は以下の通りです。
画像をVAEのエンコーダーに通して潜在変数へ変換する。
潜在変数を拡散モデルのエンコーダーに通してノイズを加える。
ノイズが加わった潜在変数をUNetでデノイズ(ノイズ除去)する。
デノイズされた潜在変数をVAEのデコーダーに通して元の画像に変換する。
基本は上記の流れで画像が生成されますが、Stable Diffusionではここにテキスト情報を追加することで、そのテキストに沿った画像を生成できるように工夫されています。 簡単なStable Diffusionの説明は以上ですが、ここで言いたいことは、今まで実装してきたVAEと今回実装する拡散モデルを学習することで、あの有名なStable Diffusionの根本に触れることができるということです。 もちろん、公表されているモデルは他の工夫点が沢山盛り込まれていると思いますが、基本を押さえることはとても重要なので見ていきましょう。
STEP 9.2:拡散モデルの拡散過程(エンコーダー)の実装
まずは拡散モデルのエンコーダーとも呼べる拡散過程の実装を行っていきます。 拡散過程は簡単に言うと画像にノイズを加えていくモデルで、数式で表すと以下のようになります。
ここでは
回ノイズが加えれた画像データだと思ってください。ざっくり言うと、
回ノイズが加えられた画像
を中心として、その画像に少しガウスノイズを加えたものが
となります。
また、
は自前で決めるパラメータになっており、どのくらいのスピードでノイズを加えていくかを決定するものになります。
この値が大きいと加えるノイズの量が大きくなるため早く元の画像がノイズだらけになりますが学習がうまくいかなくなる可能性が高まります。一方、小さすぎても学習に時間がかかりすぎてしまうのでバランスが重要です。
その値の決め方は色々提案されていますが、今回は拡散モデルの原論文にそって0.0001から0.02まで線形に変化する方法を取りたいと思います。
では、ここまで実装してみます。今回使用する画像はWebから適当にとってきた以下の画像(Stable Diffusionから生成された画像)です。 こちらの画像にノイズを徐々に加えていきます。ちなみに、コード中に「cimg2tensor」とありますが、これは自前の関数でimagerパッケージでロードした画像をtorchパッケージで使用するテンソルへ変換するものです。 もっと良いやり方があるのかもしれませんが、Rの画像系パッケージとtorchパッケージの相性は左程良くなく、少し次元の整理をしなくてはならないので手間ですね。。

library(imager) cimg2tensor = function(img, iscolor = T){ img_array = img %>% as.array() img_dim = dim(img_array) color_dim = ifelse(iscolor,3,1) tmp = array(NA,dim = c(img_dim[1],img_dim[2],color_dim)) tmp[,,1:color_dim] = img_array[,,1,1:color_dim] tmp[1:img_dim[1],,] = img_array[1:img_dim[1],,1,] tmp[,1:img_dim[2],] = img_array[,1:img_dim[2],1,] out = torch_tensor(tmp) return(out) } img = load.image("./data/image.png") x = cimg2tensor(img) MAX_T = 1000 betas = torch_linspace(0.0001, 0.02, MAX_T) plot_list = list() plot_num = 1 for(t in 1:MAX_T){ if(t %% 100 == 0){ img = tensor2cimg(x) plot_list[[plot_num]] = img plot_num = plot_num + 1 } beta = betas[t] eps = torch_randn_like(x) x = torch_sqrt(1-beta) * x + torch_sqrt(beta) * eps } #描写 par(mfrow=c(2,5)) par(oma = c(1, 1, 1, 1)) for(i in 1:10){ plot_list[[i]] %>% plot(axes = FALSE, main = paste("t =", i*100)) }

このように元の画像にノイズを加えていくことで、最終的にはノイズだけになる様子が見て取れるかと思います。
しかし、モデルの学習のためには大量の画像データが必要であり、その画像1つ1つに上記のように徐々にノイズを加えていく方法だと学習時間が大変なことになってしまいます。
そこで、加えているノイズがガウスノイズであることに注目すると、正規分布+正規分布=正規分布という正規分布の再生性の性質を上手く利用できそうです。
その性質を活用すると元の画像からノイズを
回加えた画像
へ一気に飛ぶことができます。数式で書くと以下の通りです。
これを実装すると以下のようになります。また、冒頭の「tensor2cimg」はtorchパッケージのテンソルからimagerパッケージの画像形式へ変換する自前の関数です。 そのため、拡散モデルには関係ないところなので飛ばしていただいて大丈夫です(急にコード内に出てきたらtorchパッケージの関数だと誤解される可能性があると思い載せています)。
tensor2cimg = function(tensor, iscolor = T){ tensor = tensor * 255 tensor = tensor$clamp(0,255) tensor = tensor/ 255 tensor_array = tensor %>% as.array() tensor_dim = dim(tensor_array) color_dim = ifelse(iscolor,3,1) tmp = array(NA,dim = c(tensor_dim[1],tensor_dim[2],1,color_dim)) tmp[,,1,1:color_dim] = tensor_array[,,1:color_dim] tmp[1:tensor_dim[1],,1,] = tensor_array[1:tensor_dim[1],,] tmp[,1:tensor_dim[2],1,] = tensor_array[,1:tensor_dim[2],] out = as.cimg(tmp) return(out) } beta_start = 0.0001 beta_end = 0.02 MAX_T = 1000 betas = torch_linspace(beta_start,beta_end,MAX_T) add_noise = function(x_0,t,betas){ MAX_T = length(betas) if(!(t>=1 & t<=MAX_T)){ stop("ERROR\n") }else{ alphas = 1 - betas alpha_bars = torch_cumprod(alphas, dim = 1) alpha_bar = alpha_bars[t] eps = torch_randn_like(x_0) x_t = torch_sqrt(alpha_bar) * x_0 + torch_sqrt(1 - alpha_bar) * eps } return(x_t) } img = load.image("./data/image.png") x = cimg2tensor(img) x = add_noise(x,100,betas) img_add_noise = tensor2cimg(x) plot(img_add_noise, axes = FALSE)

画像を見る限りうまくいってそうですね。これでエンコーダー部分の実装は完了です。
STEP 9.3:拡散モデルのU-Net(デコーダー)の実装
拡散モデルのデコーダーにはU-Netが使用されることが多いみたいです。他にもSelf-AttentionやTransformerなども考えられているようですが、使用する画像の複雑さなどから使用するモデルを選択すればよいかと思います。 今回の学習ではMNISTの数字画像のデータを使用するので、U-Netでも十分な性能がある判断してその実装を進めていきます。U-Netに関する細かい説明はWebや原論文など至る所に転がっているので大部分は割愛し、簡単な説明のみ記載します。
U-Netは以下の画像のような構造を持つモデルで、モデルの構造が画像の通りU字であることからU-Netという名前がついているようです。 内容としてはそこまで複雑ではなくCNNを繰り返すのですが、一番の特徴はスキップ接続であり、モデル構造における縮小ステージと拡大ステージの間で情報を直接伝える機構がついています。 これにより、画像全体の特徴と細かい部分の特徴を合わせて処理を行うことが可能になります。

また、上記で実装した通り、拡散モデルでは拡散過程を通して回ノイズを加えた画像を使用して学習をしていきます。
そのため、U-Netにインプットした画像が何回ノイズを加えた画像なのかを知らせる必要があります。これは時系列系のモデルでもよく使用されている正弦波位置エンコーディングを使用します。
以上のことをまとめると、拡散モデルのデコーダーにはU-Netを使用し、そのインプットは回ノイズを加えた画像
と、その画像が何回ノイズを加えたものなのかを知らせる変数
となります。
これらのことを実装すると以下のようになります。
#正弦波位置エンコーディングの実装 pos_encoding_t = function(t, out_dim, device = "cpu"){ D = out_dim v = torch_zeros(D, device = device) i = torch_arange(0,D,device = device) div_term = 10000 ** (i/D) v[seq(2,D,2)] = torch_sin(t / div_term[seq(2,D,2)]) v[seq(1,D,2)] = torch_cos(t / div_term[seq(1,D,2)]) return(v) } pos_encoding = function(ts, out_dim, device = "cpu"){ batch_size = length(ts) v = torch_zeros(batch_size, out_dim, device = device) for(i in 1:batch_size){ v[i] = pos_encoding_t(ts[i], out_dim, device) } return(v) } #U-Netで使用する画像処理ブロック(内容としてはCNNと正弦波位置エンコーディングの組み合わせ) ConvBlock <- nn_module( initialize = function(in_dim,out_dim,time_embed_dim) { self$conv = nn_sequential( nn_conv2d(in_dim,out_dim,3,padding = 1), nn_batch_norm2d(out_dim), nn_relu(), nn_conv2d(out_dim,out_dim,3,padding = 1), nn_batch_norm2d(out_dim), nn_relu() ) self$mlp = nn_sequential( nn_linear(time_embed_dim, in_dim), nn_relu(), nn_linear(in_dim,in_dim) ) }, forward = function(x,v) { shape = x$shape v = self$mlp(v) v = v$reshape(c(shape[1], shape[2], 1, 1)) return(self$conv(x+v)) } ) #U-Netの実装 UNet <- nn_module( initialize = function(in_dim=1, time_embed_dim = 100) { self$time_embed_dim = time_embed_dim self$down1 = ConvBlock(in_dim,64,time_embed_dim) self$down2 = ConvBlock(64,128,time_embed_dim) self$bot1 = ConvBlock(128,256,time_embed_dim) self$up2 = ConvBlock(128+256,128,time_embed_dim) self$up1 = ConvBlock(128+64,64,time_embed_dim) self$out = nn_conv2d(64,in_dim, 1) self$maxpool = nn_max_pool2d(2) self$upsample = nn_upsample(scale_factor = 2, mode = "bilinear") }, forward = function(x, timesteps) { v = pos_encoding(timesteps, self$time_embed_dim, x$device) x1 = self$down1(x,v) x = self$maxpool(x1) x2 = self$down2(x,v) x = self$maxpool(x2) x = self$bot1(x,v) x = self$upsample(x) x = torch_cat(c(x,x2),dim = 2) x = self$up2(x,v) x = self$upsample(x) x = torch_cat(c(x,x1), dim = 2) x = self$up1(x,v) x = self$out(x) return(x) } )
STEP 9.4:拡散モデルの実装
では、今まで紹介した内容を整理して拡散モデルを実装していきます。 以下のコードでは、上記に記載した画像にノイズを加える機構とU-Netでデノイズする機構を入れています。 また、学習後に画像を生成する機構とその生成した画像をimagerパッケージの形式に沿った画像に変換する機構も併せて実装しています。
Diffuser <- nn_module( initialize = function(num_timesteps=1000, betas_start=0.0001, beta_end=0.02, device = "cpu") { self$num_timesteps = num_timesteps self$device = device self$betas = torch_linspace(betas_start,beta_end,num_timesteps,device = device) self$alphas = 1 - self$betas self$alpha_bars = torch_cumprod(self$alphas, dim=1) }, add_noise = function(x_0,t){ MAX_T = length(self$num_timesteps) alpha_bar = self$alpha_bars[t %>% as.array()] N = alpha_bar$size(1) alpha_bar = alpha_bar$view(c(N,1,1,1)) noise = torch_randn_like(x_0,device = self$device) x_t = torch_sqrt(alpha_bar) * x_0 + torch_sqrt(1 - alpha_bar) * noise return(list(x_t,noise)) }, denoise = function(model,x,t) { MAX_T = self$num_timesteps alpha = self$alphas[t %>% as.array()] alpha_bar = self$alpha_bars[t %>% as.array()] alpha_bar_prev = self$alpha_bars[(t-1) %>% as.array()] N = alpha_bar$size(1) alpha = alpha$view(c(N,1,1,1)) alpha_bar = alpha_bar$view(c(N,1,1,1)) alpha_bar_prev = alpha_bar_prev$view(c(N,1,1,1)) model$eval() with_no_grad({ eps = model(x,t) model$train() noise = torch_randn_like(x, device = self$device) noise[t == 2] = 0 mu = (x -((1-alpha) / torch_sqrt(1-alpha_bar)) * eps) / torch_sqrt(alpha) std = torch_sqrt((1-alpha) * (1-alpha_bar_prev) / (1-alpha_bar)) return(mu + noise * std) }) }, reverse_to_img = function(x, iscolor = F) { tensor = x * 255 tensor = tensor$clamp(0,255) tensor = tensor/ 255 tensor_array = tensor %>% as.array() tensor_dim = dim(tensor_array) color_dim = ifelse(iscolor,3,1) out = list() for(i in 1:tensor_dim[1]){ tmp = array(NA,dim = c(tensor_dim[3],tensor_dim[4],1,color_dim)) tmp[,,1,1:color_dim] = tensor_array[i,1:color_dim,,] tmp[1:tensor_dim[3],,1,] = tensor_array[i,,1:tensor_dim[3],] tmp[,1:tensor_dim[4],1,] = tensor_array[i,,,1:tensor_dim[4]] out[[i]] = as.cimg(tmp) } return(out) }, make_sample = function(model, x_shape = c(20,1,28,28)){ batch_size = x_shape[1] x = torch_randn(x_shape, device = self$device) for(i in self$num_timesteps:2){ t = torch_tensor(rep(i,batch_size), device = self$device, dtype = torch_long()) x = self$denoise(model, x, t) } return(x) } )
これで拡散モデルを実装することができましたので、実際に学習していきます。 学習に使用するデータはtorchvisionパッケージからMNISTの数字画像データを取ってきます。 CPUで学習するにはかなり時間がかかるのでご注意ください。私はepochを80回程度で止めてしまいましたが、10時間以上かかってしまいました。 (参考書にもCPUだと1epochごとに10分程度かかると記載があります。)
library(torchvision) img_size = 28 batch_size = 128 num_timesteps = 1000 epochs = 100 lr = 10^-3 device = ifelse(cuda_is_available(),"cuda","cpu") ds <- mnist_dataset( root = "./data", train = TRUE, # default download = TRUE, transform = function(x) { y = x %>% transform_to_tensor() } ) dl <- dataloader(ds, batch_size = batch_size, shuffle = TRUE) diffuser = Diffuser(num_timesteps,device = device) model = UNet() optimizer = optim_adam(model$parameters, lr=lr) losses = c() for(epoch in 1:epochs){ loss_sum = 0.0 cnt = 0 coro::loop(for(img in dl){ optimizer$zero_grad() x = img$x shape = x$shape t = torch_randint(1, num_timesteps,shape[1],device = device) x_noisy = diffuser$add_noise(x,t) noise_pred = model(x_noisy[[1]],t) loss = nnf_mse_loss(x_noisy[[2]],noise_pred,reduction = "sum") loss$backward() optimizer$step() loss_sum = loss_sum + loss$item() cnt = cnt + 1 }) loss_avg = loss_sum / cnt losses = c(losses, loss_avg) cat("Epoch: ",epoch,"| Loss: ", loss_avg) }
こちらのコードで学習した結果を示していきたいと思います。 まずは損失関数の推移ですが、以下の通りでした。順調に値が減っていることがわかるかと思います。 今回は80epochくらい回しましたが、半分の40epochくらいでも十分に損失が減っているので学習時間はもっと減らせそうですね。
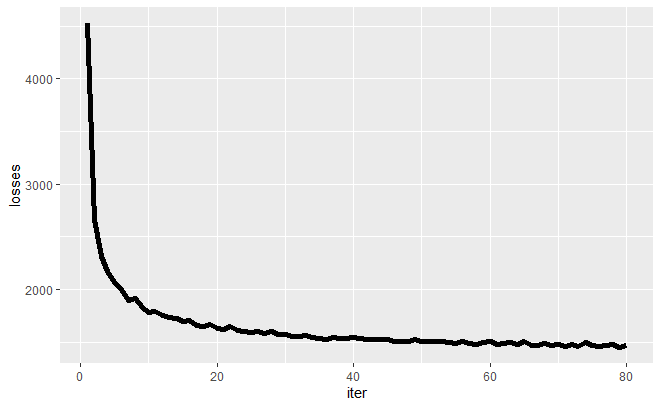
次に、学習したモデルから画像を生成してみたいと思います。 Rコードは以下の通りです。最後のplot部分で画像の細かい位置調整をしていますが、ここら辺はもう少しうまく実装すればこのような調整は不要かもしれません。。
tmp = diffuser$make_sample(model = model, x_shape = c(10,1,28,28)) gen_img = diffuser$reverse_to_img(tmp) par(mfrow=c(2,5)) par(oma = c(1, 1, 1, 1)) for(i in 1:10){ plot(gen_img[[i]] %>% mirror(axis = "x") %>% rotate_xy(-90,14,14), axes = FALSE) }
このコードで生成した画像は以下の通りです。 少し怪しい画像もありますが、VAEの時と比べて鮮明に数字とわかる画像が生成されているように思えます。 学習に時間を要しましたが、うまい具合に画像が生成できてよかったです。。

まとめ
今回は拡散モデルの実装を行いました。前回までと比べてかなり複雑化してきたので、コードも長くなってきました。 一番痛いところはやはりGPU計算の試行がうまくいっていないことですね。。これがうまくいけばトライ&エラーをもっと高速に回せるので、いつかちゃんと要因をとらえて修正していきたいと思っています。 ここら辺詳しい方はコメントいただけると大変うれしいです。。
次回
ゼロから作るDeep Learning 5(生成モデル編)をRで再現してみた(第七章)
前回
はじめに
前回はニューラルネットをtorchパッケージを使用して実装してみました。今回は変分オートエンコーダー(VAE)を同じような形で実装していきます。 VAEは今後紹介する生成モデルの基礎となるモデルになります。今までもそうでしたが、参考書のpythonコードをすべてRコードで再現するのではなく、それらを要約しつつ個人的にわかりやすいように一部変更しながらコードを書いています。 その点について留意いただきながらご覧になっていただけますと幸いです。
STEP 7.1:混合ガウスモデル(GMM)と変分オートエンコーダー(VAE)の違いについて
振り返りも含めてGMMとVAEの違いについて触れていきます。GMMは正規分布を複数(K個)用意して、その中の正規分布を1つ選んでそこからデータが得られたと考える生成モデルです。つまり、潜在変数はK個のうち1つを選択するカテゴリカル分布に従います。 一方、VAEは潜在変数を正規分布として設定し、その潜在変数をニューラルネットに通すことでデータを再現するモデルです。
記載した通り、GMMとVAEは潜在変数の設定が異なります。GMMはカテゴリカル分布なので離散的な分布ですが、VAEは正規分布なので連続的な分布です。そのため、より細かい粒度で潜在変数を表現することができる可能性があります。 また、GMMは潜在変数から選択した正規分布からデータを得られたと仮定しますが、VAEはニューラルネットを用いているためより柔軟な表現力を持つと考えられます。
一方、VAEはGMMより複雑なモデルであるため、パラメータ推定は一般的により困難になります。そのため、例えばデータ数が少ないと収束しなかったり局所解に陥る可能性が相対的に高いと考えられ、そのようなモデルリスクがあることには留意が必要かもしれません。
STEP 7.2:VAEの学習
GMMとVAEの違いについて簡単に紹介しましたが、大きな違いとしては潜在変数が離散から連続に変わったことです。その違いにより前回紹介したEMアルゴリズムを直接使用することができず、学習するためにはひと手間かかってしまいます。 その点について触れていきます。まず、VAEの対数尤度は以下のように計算できます。
EMアルゴリズムと同様に第一項目がELBO、第二項目がKLダイバージェンスになります。EMアルゴリズムではとすればよかったのですが、VAEでは直接
を求めることが難しいのでこの手が使えません。
そのため、
と仮定して計算していきます。このように直接計算不可能な分布に対して、その分布を近似する計算可能な分布を設定して計算していく方法を変分近似や変分ベイズと呼ばれます。変分オートエンコーダーの変分はここから来ています。
では、このをどのように推定していけばよいのでしょうか?結論から言うと、ELBOにも
が含まれているのでELBOが最大になるように
を更新すれば、それが結局
が
に一番近づくようになります。これは、そもそもの対数尤度は
をパラメータとして持たないので、
をどのように動かしても対数尤度の値は変わりません。つまり、第一項目のELBOが
に対して最大化される→第二項目のKLダイバージェンスが最小になる→
が
に一番近づくということになります。
では、より具体的にの推定の仕方を見ていきます。
は潜在変数の分布を決定付けるパラメータなので、データ
が得られたときに潜在変数がどのような分布になるかがわかればOKです。
よって、VAEではデータ
をインプットして潜在変数の分布のパラメータである
を出力するニューラルネットを用いて推定していきます。このようにデータから潜在変数のパラメータを求めるのは、エンコーダー(Encoder)と呼ばれています。
逆に潜在変数からデータを生成するモデルをデコーダー(Decoder)と呼びます。(※以降、デコーダー・エンコーダーの意味合いは知っている前提で文章やコードを記載していきますのでご注意ください)
ここまでの内容をまとめますと、まずエンコーダーでデータから潜在変数の分布を推定します。そして、その分布から得られた潜在変数をデコーダーに通してデータを生成します。 このようにデータをインプットして、そのデータを複製するようなモデルのことをオートエンコーダーと言い、先ほどの変分の話と合わせて変分オートエンコーダー(VAE)と呼ばれています。 VAEのパラメータを決定できれば、後は潜在変数を好きなだけ生成してデコーダーに通せば、もともとのデータの特徴を持ったデータを生成することができるようになります。
STEP 7.3:VAEの実装
ここではVAEの実装をしていきます。詳細な計算は参考書をご覧になっていただければと思いますが、ELBOは以下のように近似計算することができます。
ここではモデルからサンプリングしたデータになります。これはELBO内の期待値の計算をするためにデータを1つサンプリングした結果を基にその期待値を計算しています。
もし、期待値計算するときにもっとデータを増やした方がよいということであれば、複数データをサンプリングしてその結果を平均すればOKです。
参考書によると、データ数が1個でもVAEの場合はうまく推定ができる可能性が高いとのことです。
このELBOを用いて実装したRコードは以下の通りです。
#Encoderを実装 Encoder <- nn_module( initialize = function(input_dim, hidden_dim, latent_dim) { self$linear = nn_linear(input_dim, hidden_dim) self$linear_mu = nn_linear(hidden_dim, latent_dim) self$linear_logvar = nn_linear(hidden_dim, latent_dim) }, forward = function(x) { h = self$linear(x) h = nnf_relu(h) mu = self$linear_mu(h) logvar = self$linear_logvar(h) sigma = torch_exp(0.5 * logvar) latent_params = list(mu, sigma) return(latent_params) } ) #Decoderを実装 Decoder <- nn_module( initialize = function(latent_dim, hidden_dim, output_dim) { self$linear_1 = nn_linear(latent_dim, hidden_dim) self$linear_2 = nn_linear(hidden_dim, output_dim) }, forward = function(z) { h = self$linear_1(z) h = nnf_relu(h) h = self$linear_2(h) x_hat = nnf_sigmoid(h) return(x_hat) } ) #パラメータ推定のためのreparameterize reparameterize = function(params){ mus = params[[1]] sigmas = params[[2]] eps = torch_randn_like(sigmas) z = mus + eps * sigmas return(z) } #VAEを実装 VAE <- nn_module( initialize = function(input_dim, hidden_dim, latent_dim) { self$encoder = Encoder(input_dim,hidden_dim,latent_dim) self$decoder = Decoder(latent_dim,hidden_dim,input_dim) }, getloss = function(x) { params = self$encoder(x) z = reparameterize(params) x_hat = self$decoder(z) L1 = nnf_mse_loss(x_hat,x, reduction = "sum") L2 = - torch_sum(1 + torch_log(params[[2]] ** 2) - params[[1]] ** 2 - params[[2]] ** 2) return((L1+L2)/batch_size) } )
エンコーダーを実装する際、list型でを返すような関数を組んでいます。
pythonの場合は複数の返値を並行して設定することができますが、Rの場合はこのようにlist型で返すことが一般的な気がします。
ここら辺はpythonのほうが実装しやすいかもしれないですね。
STEP 7.4:VAEの学習
最後に実際のデータをVAEに通して学習してみましょう。 先程のVAEコードにMNISTデータをインプットして学習していきます。MNISTデータはtorchvisionパッケージから取得しています。 先程のRコードもそうですが、ここら辺になってくると参考書のpythonコードとRコードでは記法が若干異なってきますね。
library(torchvision) # ハイパーパラメータの設定 input_dim = 784 hidden_dim = 200 latent_dim = 20 epochs = 1000 learning_rate = 3 * 10^-4 batch_size = 32 ds <- mnist_dataset( root = "./data", train = TRUE, # default download = TRUE, transform = function(x) { y = x %>% transform_to_tensor() y = torch_flatten(y) } ) dl <- dataloader(ds, batch_size = batch_size, shuffle = TRUE) model = VAE(input_dim, hidden_dim, latent_dim) optimizer = optim_adam(model$parameters, lr = learning_rate) losses = c() x = dl %>% dataloader_make_iter() %>% dataloader_next() for(epoch in 1:epochs){ loss_sum = 0 cnt = 0 for(in_x in 1:batch_size){ optimizer$zero_grad() loss = model$getloss(x$x[in_x]) loss$backward() optimizer$step() loss_sum = loss_sum + loss$item() cnt = cnt + 1 } loss_avg = loss_sum / cnt losses = c(losses, loss_avg) print(loss_avg) } losses_plot = bind_cols(1:epochs,losses) names(losses_plot) = c("epochs", "losses") ggplot(losses_plot) + geom_line(aes(x=epochs, y=losses))
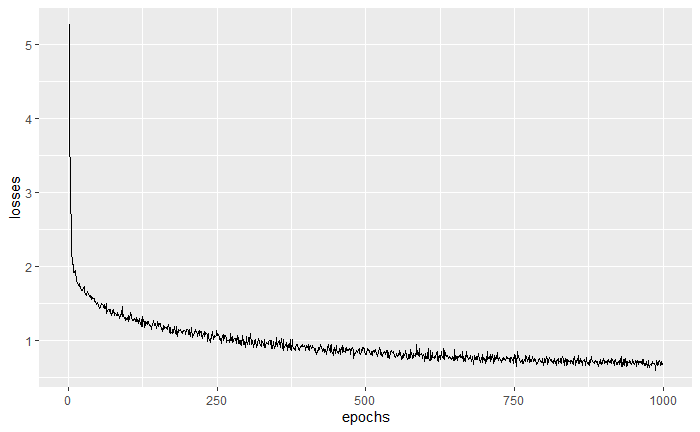
参考書に載っているVAEの損失関数とは水準感と推移の仕方が異なっているように見えますが、損失自体は問題なく小さくなっています。(参考書のグラフは滑らか過ぎるので何か加工している?) また、十分に学習するためにはエポック数を大きくする必要があった点も参考書とは異なっていました。あくまで参考書ということで、本稿では自分である程度満足する結果が出るように設定を変えたりしていますのでご注意ください。 最後に、学習したVAEで画像を生成してみようかと思います。
library(imager) plot_list = list() for(i in 1:16){ with_no_grad({ sample_size = 1 z = torch_randn(sample_size, latent_dim) x = model$decoder(z) generated_images = x$view(c(sample_size,28, 28)) }) tmp = generated_images %>% as.array() tmp_min = min(tmp) tmp_max = max(tmp) tmp = (tmp - tmp_min) / tmp_max plot_list[[i]] = as.cimg(t(tmp[1,,])) } par(mfrow = c(4,4)) for(i in 1:16){ plot(plot_list[[i]]) }
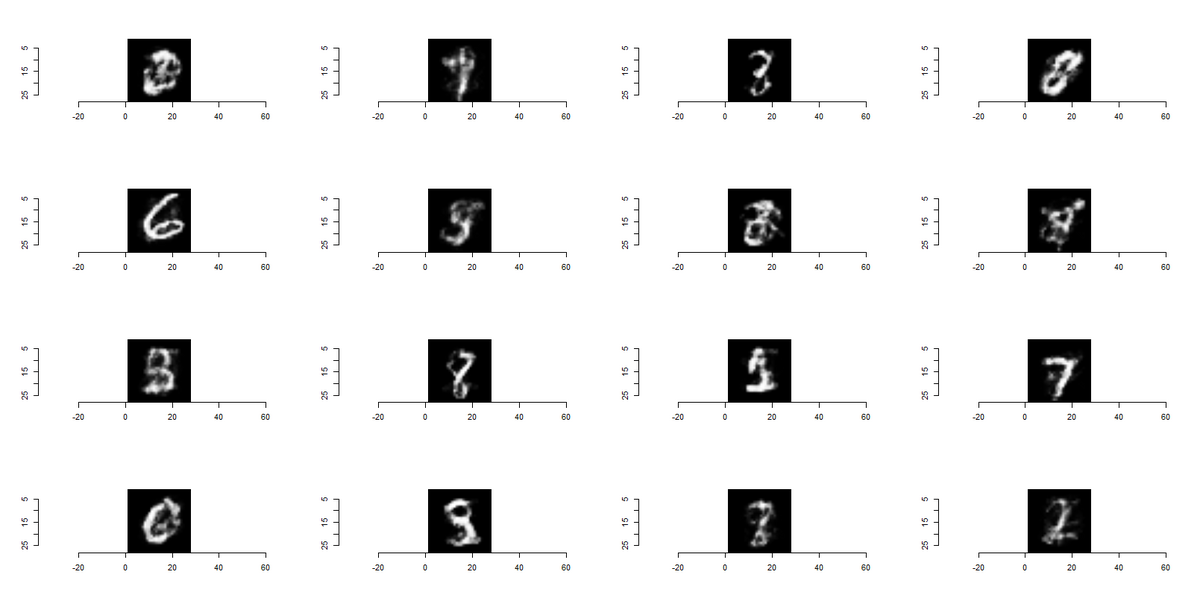
ここら辺の画像の出し方はpythonのほうが楽な気がします(私がRにおける画像の扱いに慣れていないことが大きいのですが・・・)。 画像の出し方は乱数を発生させてVAEのデコーダーにインプットすれば作成することができます。 少し画質が荒い感じもしますが、「8」だったり「6」だったり様々な数値の画像が得られていることがわかります。 ここからVAEの学習は一定程度うまくいっているように思えます。
まとめ
今回はVAEを実装してみました。徐々にRコードとpythonコードに差が出始めてきたので、参考書を見るだけでは実装が難しくなってきました・・・。 少しずつ記事を書くスピードが落ちるかもしれませんが、次回以降の章も頑張って実装していこうかと思います。
次の記事
ゼロから作るDeep Learning 5(生成モデル編)をRで再現してみた(第六章)
前回
はじめに
前回はEMアルゴリズムについて紹介しました。今回は生成モデルを作るにあたって重要なファクターであるニューラルネットワークについて触れていきます。ニューラルネットワークなどの深層学習系のモデル構築ではpythonが一般的には使用されているかと思います。Rはそもそも統計解析専門のプログラミング言語であり、深層学習などを含んだ機械学習に関してはpythonより一歩遅れているイメージがあります(その一方、ARIMA系やGARCH系のモデル、相関周りはCopulaなどを活用したモデルなどの多変量時系列分析はまだRの方が強い気がする)。
数年前ではありますが、RにもtorchやlightGBMのパッケージが登場しており、Rでも十分に深層学習・機械学習ができるようになってきました。しかし、やはり深層学習系の実装にはpythonが使われるためか、Rにおけるtorchの使い方などを紹介しているブログがかなり少ないため、このブログが参考になればいいなと思っています(とは言え、メインはtorchパッケージの使い方の説明ではなく、Rで参考書の結果の再現することなので、torchの説明を割愛する部分も多いことにはご容赦ください)。
STEP 6.1:torchパッケージによるテンソル計算
pythonでもRでもtorchではテンソルと呼ばれるクラスを用意して計算していきます。テンソルはざっくり言うと、変数の値とともに最適化の際に使用する勾配の情報を併せ持つクラスです。と言っても、中々わかりにくいと思うので実際の例を見てみましょう。
library(torch) x = torch_tensor(5.0,requires_grad = TRUE) y = 3 * x ** 2 y$backward() print(x$grad)
torch_tensor 30 [ CPUFloatType{1} ]
この例はの
のときの傾き(勾配)を求めるコードになっています。
なので
の時の傾きは30になります。Rコードによる結果も30が返ってきているので問題なく勾配が計算できていることがわかります。このようにtorchではテンソルを設定して、そのテンソルを使って計算して勾配を求めることができます。これを活用していってニューラルネットワークのパラメータを推定することができるようになります。
STEP 6.2:より実用的な例
先程は1変量の関数の勾配について求めてみました。次により複雑な2変量の関数の勾配も求められることを確認していきます。
こちらの関数はローゼンブロック関数と呼ばれており、関数の形状が複雑なので最小値の検索が難しいことが知られています。この関数の勾配や最小値は陽に出せるので、torchで計算した結果とその解析解が一致していることを確認します。torchによる勾配算出は以下の通りです。
rosenbrock = function(x0,x1) { y = 100 * (x1 - x0 ** 2) **2 + (x0 - 1) ** 2 return(y) } x0 = torch_tensor(0.0, requires_grad = TRUE) x1 = torch_tensor(2.0, requires_grad = TRUE) y = rosenbrock(x0,x1) y$backward() x0$grad x1$grad # 以下出力 > x0$grad torch_tensor -2 [ CPUFloatType{1} ] > x1$grad torch_tensor 400 [ CPUFloatType{1} ]
torchによると、のときの勾配は
方向は
であり、
方向は
であると算出されました。詳細は割愛しますが、この結果は解析的に算出する結果と一致しています。ここからもtorchでは多変量の関数の勾配を問題なく計算できることがわかります。
STEP 6.2:torchによる勾配法
先程は勾配を計算しましたが、その勾配の情報から関数を最小化・最大化させる引数を求めることができます。ざっくり言うと、関数を山で例えると勾配は山頂へ進む方向を示しています。そのため、勾配の方向と逆の方向へ行けば、その関数の出力が最小になる場所(引数)を求められることが期待できます(局所解に陥る可能性があるため必ずたどり着くわけではないことに注意)。
このように勾配を使って関数の最小値・最大値を求める方法を勾配法と呼びます。この勾配法をRで記載すると以下のようになります。
#引数 x0 = torch_tensor(0.0, requires_grad = TRUE) x1 = torch_tensor(2.0, requires_grad = TRUE) #学習率と学習回数 lr = 0.001 iters = 10000 #勾配法の適用 for(i in 1:iters) { if(i %% 1000 == 0) { print(paste("x0の更新値-->",x0$item())) print(paste("x1の更新値-->",x1$item())) } y = rosenbrock(x0,x1) y$backward() with_no_grad({ #値の更新 x0 = x0$sub_(lr * x0$grad) x1 = x1$sub_(lr * x1$grad) # 勾配のリセット x0$grad$zero_() x1$grad$zero_() }) } print(x0$item()) print(x1$item())
[1] "x0の更新値--> 0.683491885662079" [1] "x1の更新値--> 0.465650737285614" [1] "x0の更新値--> 0.826225161552429" [1] "x1の更新値--> 0.681877732276917" [1] "x0の更新値--> 0.894734084606171" [1] "x1の更新値--> 0.80010062456131" [1] "x0の更新値--> 0.933457612991333" [1] "x1の更新値--> 0.871066033840179" [1] "x0の更新値--> 0.956970870494843" [1] "x1の更新値--> 0.915616571903229" [1] "x0の更新値--> 0.97180449962616" [1] "x1の更新値--> 0.944289207458496" [1] "x0の更新値--> 0.981372833251953" [1] "x1の更新値--> 0.963017225265503" [1] "x0の更新値--> 0.987630069255829" [1] "x1の更新値--> 0.975363254547119" [1] "x0の更新値--> 0.991757750511169" [1] "x1の更新値--> 0.983550250530243" [1] "x0の更新値--> 0.994495928287506" [1] "x1の更新値--> 0.989000022411346" [1] 0.9944981 [1] 0.9890044
このように、や
を更新していくことで徐々に関数の最小値となる場所へ向かっていきます。
コード上では、一回値を更新したら前回の勾配の情報は不要となるので、grad$zero_関数で勾配を0に初期化しています。
このようにtorch用の実装をする必要があるため、ここら辺は慣れていく必要があるかと思います。
結果としては、参考書の数値とほぼ同じものが得られており、問題なく勾配法で最適化(最小化・最大化)ができていると考えてよいでしょう。
STEP 6.3:torchによる回帰分析(線形回帰)
次はより機械学習に近づくために線形回帰を実装してみます。線形回帰自体は他のブログや参考書に多く紹介されているので、ここでは詳細な内容は割愛しますが、Rのtorchパッケージで実装している例は少ないと思いますので、Rコードメインで載せたいと思います。
例としてという関係式を設定して、
に適当な乱数を当てはめ、その値から
を算出していきます。
そして得られたシミュレーションデータを回帰分析に当てはめてみます。
# データ作成 torch_manual_seed(0) x = torch_rand(100,1) y = 2 * x + 5 + torch_rand(100,1) #回帰分析の係数設定 W = torch_zeros(c(1,1), requires_grad = T) b = torch_zeros(1, requires_grad = T) #回帰モデルの予測 predict_lm = function(x) { y = x$matmul(W) + b return(y) } #損失関数 MSE = function(x0,x1) { dif = x0 - x1 N = nrow(dif) return(torch_sum(dif ** 2) / N) } #学習率と学習回数 lr = 0.1 iters = 100 #勾配法の適用 for(i in 1:iters) { y_hat = predict_lm(x) loss = MSE(y, y_hat) loss$backward() with_no_grad({ #値の更新 W = W$sub_(lr * W$grad) b = b$sub_(lr * b$grad) # 勾配のリセット W$grad$zero_() b$grad$zero_() }) if(i %% 10 == 0) { print(paste("loss-->",loss$item())) } } paste("W -->",W$item()) paste("b -->",b$item())
[1] "loss--> 0.36120480298996" [1] "loss--> 0.110804900527" [1] "loss--> 0.105388298630714" [1] "loss--> 0.101745866239071" [1] "loss--> 0.0988810658454895" [1] "loss--> 0.0966264083981514" [1] "loss--> 0.0948518961668015" [1] "loss--> 0.0934552848339081" [1] "loss--> 0.0923561081290245" [1] "loss--> 0.0914910137653351" [1] "W --> 2.19477248191833" [1] "b --> 5.45298910140991"
結果から損失関数(平均二乗誤差)はパラメータ(引数)が更新されるにつれて減っていることがわかるかと思います。
そして得られたパラメータはであり、元の回帰式の数値とかなり近い数値になっていることがわかるかと思います。
このようにしてtorchで回帰分析を行うことができます(そのほかにもtorchの関数を使って様々な回帰分析のパラメータ最適化ができるのですが、別の機会に紹介できればと思います)。
STEP 6.4:torchによる回帰分析(ニューラルネット)
最後に、非線形関数から取得したデータにニューラルネットを適用してみましょう。
ニューラルネットは、一定の条件のもと任意の関数を所望の精度で近似できることが証明されています(普遍性定理)。普遍性定理については私も深く理解できていませんが、ニューラルネットはとても柔軟な表現力を持つと考えてよいでしょう。今回は簡単な例としてをニューラルネットで近似していきます。Rコードは以下の通りです。
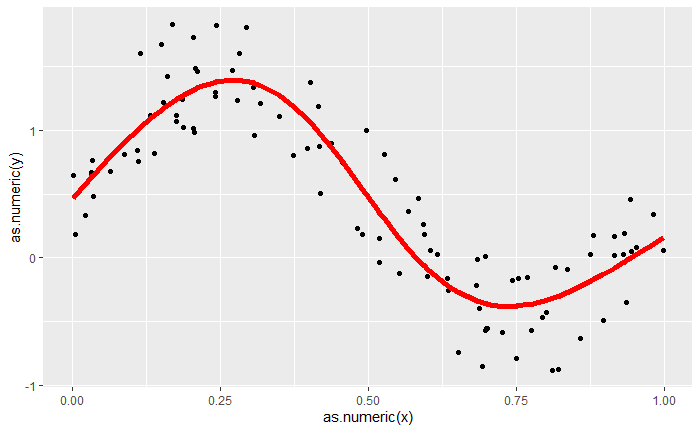
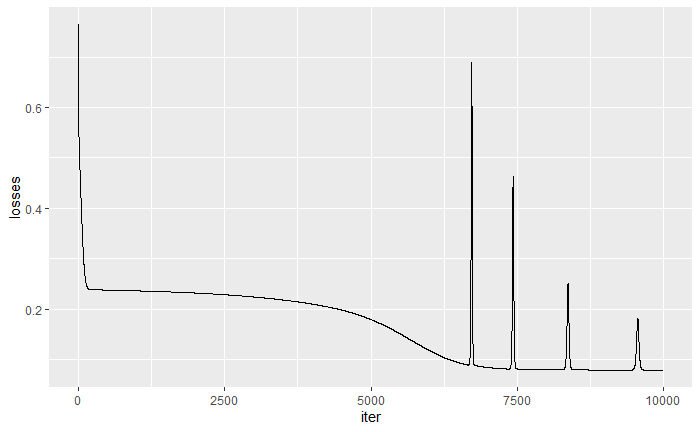
torch_manual_seed(0) #変数設定 d_in = 1 d_hidden = 10 d_out = 1 learning_rate = 0.2 loss_history = c() #データ作成 x = torch_rand(100, 1) y = torch_sin(2*pi*x) + torch_rand(100,1) #ニューラルネットワークのレイヤー設定 my_linear <- nn_sequential( nn_linear(d_in, d_hidden), nn_sigmoid(), nn_linear(d_hidden, d_out) ) #optimizerの設定 opt <- optim_sgd(my_linear$parameters, lr = learning_rate) ### 学習開始 ---------------------------------------- for (t in 1:10000) { ### -------- モデルの予測 -------- y_pred <- my_linear(x) ### -------- 損失関数の算出 -------- loss <- nnf_mse_loss(y_pred,y) loss_history = c(loss_history,loss$item()) if (t %% 1000 == 0) { cat("Epoch: ", t, " Loss: ", loss$item(), "\n") } ### -------- 勾配法の適用 -------- opt$zero_grad() loss$backward() ### -------- パラメータ更新 -------- opt$step() } #途中結果の保持 loss_history = bind_cols(1:10000,loss_history) names(loss_history) = c("iter", "losses") #結果の図示 ggplot() + geom_point(aes(as.numeric(x),as.numeric(y))) + geom_line(aes(as.numeric(x),as.numeric(y_pred)), color = "red", linewidth = 2) ggplot(loss_history) + geom_line(aes(iter,losses))
今回の例は簡単な非線形関数を設定しているので、ニューラルネットの隠れ層も1つであり、所謂Deepではありません。 しかし、以下の結果を見るに、隠れ層が1層でも十分に非線形関数を近似できていることがわかるかと思います。しかし、損失関数の推移はパラメータ更新するにつれて基本的には小さくなっていますが、ところどころジャンプしているところがあるように見えます。これは理由がまだよくわかっていませんが、optimizerの設定などで抑えることができる可能性はあります。
まとめ
今回はニューラルネットの実装をしていきました。Rのtorchパッケージに関するブログは少ないので、少しでも足しになれば嬉しいですね。次回は前回までに紹介したGMMと今回のニューラルネットを組み合わせながら、変分オートエンコーダー(VAE)について紹介していきます。
次の記事
ゼロから作るDeep Learning 5(生成モデル編)をRで再現してみた(第五章)
前回
はじめに
前回は混合ガウスモデル(GMM)について紹介しました。今回はEMアルゴリズムについて説明します。EMアルゴリズムは隠れマルコフモデル(HMM)など潜在変数を持つモデルのパラメータ推定にも使用されるなど多くの場面で活用されています。参考書(ゼロから作るDeep Learning 5)にはEMアルゴリズムの導出について丁寧に書かれていますが、このブログで同じように全て記載してしまうと参考書の良さが丸パクリになってしまうので、詳細な導出については参考本をご覧になっていただければと思います。本稿では、メインの目的がRコードで同じような結果を出すことなので、数式やその説明などは必要最低限の内容だけ記載します。
STEP5:EMアルゴリズム
EMアルゴリズムの導出のためにはカルバック・ライブラー情報量(KLダイバージェンス)を上手い具合に活用して尤度関数を作っていきます。
まずパラメータを持つ分布を考えます。その対数尤度関数は以下のように書くことができます。
ここでは任意の確率密度関数になります。この
を上手く設定することで対数尤度関数を計算しやすくすることができます。
そしてこの第二項目がKLダイバージェンスと呼ばれる項目で必ず0以上の数値を取ります。また、第一項目がエビデンスの下界(ELBO)と呼ばれます。
このKLダイバージェンスとELBOを上手く交互に更新していくことで対数尤度関数が大きくなっていくことが証明されており、その交互に更新していくことをEMアルゴリズムと呼ばれています。
具体的にはKLダイバージェンスを0に近づけるように設定し、ELBOを最大になるようにパラメータを更新していきます。KLダイバージェンスは
となるように
を設定できれば0にすることができます。
また、ELBOは今まで通り関数をパラメータ変数で微分して0となる数値を求めることでパラメータを更新していきます。GMMの場合はELBOをパラメータ変数で微分して0となる数値は解析的に求めることができるため、実装も簡単にできます。
最後に、EMアルゴリズムでは、KLダイバージェンスを更新するステップをEステップ、ELBOを更新することをMステップと呼びます。
では、このEMアルゴリズムをGMMに適用してみましょう。詳細については参考書をご覧になっていただき、ここでは結論だけ記載します。 まずEステップですが、以下のように更新します。
次にMステップは以下のように更新していきます。
このような形でGMMのパラメータを更新(EMアルゴリズム)すると、以下の対数尤度が高くなっていくはずです。
対数尤度の上昇幅が無視できるレベルで小さくなれば結果が収束したと考えられるので、そこでパラメータの更新をストップします。 では、このEMアルゴリズムをRで実装してみます。推定に使用するデータですが、前回GMMを紹介した際に作成したGMMからサンプリングするコードを活用して、そこから25,000個データをサンプリングしました。 また、多変量正規分布の確率密度関数はmnormtパッケージのdmnorm関数を使用しています(前回実装した自前の多変量正規分布の確率密度関数でも可)。
#パラメータ初期値 phis = list() mus = list() sigmas = list() phis[[1]] = 0.5 phis[[2]] = 0.5 mus[[1]] = c(0, 50.0) mus[[2]] = c(0, 100.0) sigmas[[1]] = diag(c(1,1),nrow = 2, ncol = 2) sigmas[[2]] = diag(c(1,1),nrow = 2, ncol = 2) K = 2 #潜在変数の次元 N = nrow(dat) #データ数 MAX_ITER = 100 THRESHOLD = 10^-4 #データ1個当たりのGMM尤度 GMM = function(x,mus,sigmas,phis) { K = length(mus) y = 0 for(i in 1:K) { phi = phis[[i]] mu = mus[[i]] sigma = sigmas[[i]] tmp = phi * dmnorm(x,mean = mu, varcov = sigma,log = FALSE) y = y + tmp } return(y) } #GMMの対数尤度 GMM_likelihood = function(dat,mus,sigmas,phis) { eps = 10^-8 L = 0 N = nrow(dat) for(i in 1:N) { y = GMM(dat[i,],mus,sigmas,phis) L = L + log(y + eps) } return(L / N) } #EMアルゴリズム current_likelihood = GMM_likelihood(dat,mus,sigmas,phis) for(iter in 1:MAX_ITER) { #E STEP qs = matrix(0, nrow = N, ncol = K) for(n in 1:N) { x = dat[n,] for(k in 1:K) { phi = phis[[k]] mu = mus[[k]] sigma = sigmas[[k]] qs[n,k] = phi * multivariate_normal(x,mu,sigma) } qs[n,] = qs[n,] / rep(GMM(x,mus,sigmas,phis),K) } #M STEP qs_sum = colSums(qs) for(k in 1:K) { #phi更新 phis[[k]] = qs_sum[k] / N #mu更新 c = 0 for(n in 1:N) { c = c + qs[n,k] * dat[n,] } mus[[k]] = c / qs_sum[k] #sigma更新 c = 0 for(n in 1:N) { z = matrix(dat[n,] - mus[[k]]) c = c + qs[n,k] * z %*% t(z) } sigmas[[k]] = c / qs_sum[k] } #終了条件 print(paste0("current_likelihood-->",current_likelihood)) next_likelihood = GMM_likelihood(dat,mus,sigmas,phis) diff_lik = abs(next_likelihood - current_likelihood) if(diff_lik < THRESHOLD) { print("尤度関数の変化幅が閾値以下になったため終了") break } current_likelihood = next_likelihood } print(phis) print(mus) print(sigmas)
この実行結果が以下の通りです。
[1] "current_likelihood-->-15.2745878992021" [1] "current_likelihood-->-4.40040150152027" [1] "current_likelihood-->-4.18465653638498" [1] "current_likelihood-->-4.02958516934097" [1] "current_likelihood-->-4.02374867082427" [1] "尤度関数の変化幅が閾値以下になったため終了" > print(phis) [[1]] [1] 0.6511936 [[2]] [1] 0.3488064 > print(mus) [[1]] [1] 2.000407 54.468064 [[2]] [1] 4.301432 80.010580 > print(sigmas) [[1]] [,1] [,2] [1,] 0.07031621 0.4381252 [2,] 0.43812520 33.6305036 [[2]] [,1] [,2] [1,] 0.1704147 0.9244299 [2,] 0.9244299 35.4103630
推定された結果を見る限り、GMMのデータサンプリングでインプットしていたパラメータの数値とかなり近しい数値となっていることから、うまく推定できているように見えます。 しかし、今回は25,000個のデータから推定した結果をお見せしましたが、500個くらいだとうまく推定できない場合が発生したため、やはりGMMのような潜在変数モデルはデータ数を多く確保することが重要だと思います。 または、パラメータの初期値を極端な値ではなく、より妥当な数値に設定することで収束を早めることができる可能性があります。ここら辺はトライ&エラーだという肌感覚です。
まとめ
今回はEMアルゴリズムについて簡単に紹介しました。次回は参考書のタイトルであるDeep Learningの世界に踏み込んでいき、ニューラルネットワークについてみていきます。 そして、今まで紹介してきたGMMのロジックとニューラルネットワークを徐々に組み合わせていき、より複雑なモデルを構築していきます。
次の記事
ゼロから作るDeep Learning 5(生成モデル編)をRで再現してみた(第四章)
前回
はじめに
前回は多変量正規分布について紹介しました。 今回はより発展させて混合ガウスモデル(Gaussian Mixture Model:以下GMM)についてみていきたいと思います。 多変量正規分布は単峰性の分布であり、その表現力には限度があります。例えば、多峰性を持つデータに多変量正規分布を当てはめてもデータの特徴を表現しきれません。その場合、多変量正規分布を複数組み合わせることで多峰性をもつモデルを構築することができます。ここではその多変量正規分布の組み合わせ方についてみていきます。GMMのパラメータ推定は今までと異なり最尤推定によって解析的に解くことができないため、より高度なEMアルゴリズムと呼ばれる手法によって推定されることが一般的です。そのEMアルゴリズムについては次回詳細を紹介し、今回はすでにパラメータが与えられている前提で記載していきます。
STEP4:混合ガウスモデル(GMM)
まず多次元正規分布の確率密度関数は以下の通りです。ここでは次元数を表しています。また、
と
は多次元になったことにより、それぞれ
次元の平均ベクトルと
の分散共分散行列となっています。
ここまでは前回の内容と一緒です。次にGMMへと拡張していきます。 具体的にはGMMは以下の生成モデルと考えることができます。
このような生成モデルをGMMと呼びます。例として、ここでは2つの正規分布を組み合わせたGMMを実装してみましょう。 ここで多変量正規分布からのサンプリングはMASSパッケージのmvrnorm関数を用いています。
mus = list() sigmas = list() mus[[1]] = c(2.0, 54.5) mus[[2]] = c(4.3, 80.0) sigmas[[1]] = matrix(c(0.07,0.44,0.44,33.7), nrow = 2, ncol = 2) sigmas[[2]] = matrix(c(0.17,0.94,0.94,36.0), nrow = 2, ncol = 2) prob = 0.35 GMM_sample = function(N,mus,sigmas,prob) { choice = rbinom(n = N,size = 1,prob = prob) #二項分布のサイズを1にすることでベルヌーイ分布からのサンプリングとする x_random = c() for(i in 1:N) { mu = mus[[choice[i]+1]] sigma = sigmas[[choice[i]+1]] x = mvrnorm(n = 1, mu = mu, Sigma = sigma) x_random = rbind(x_random,x) } return(x_random) } result = GMM_sample(N = 500,mus = mus,sigmas = sigmas,prob = prob) ggplot() + geom_point(aes(x = result[,1], y = result[,2])) + labs(x = "x1", y = "x2")
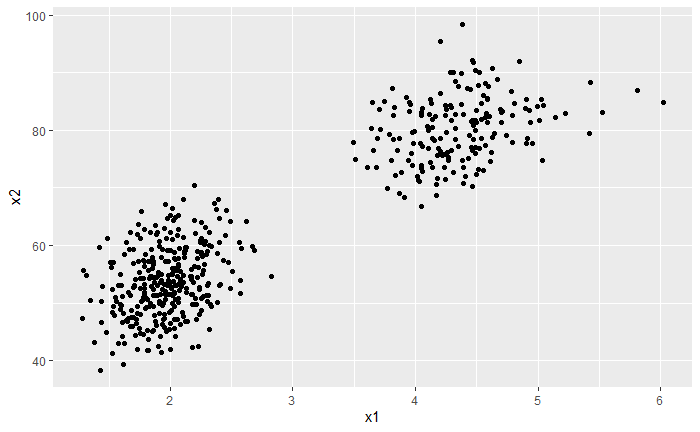
このコードでは二項分布からサンプリングする関数であるrbinomを活用して、2つの正規分布のうちどちらからサンプリングするかをランダムに決めています(他にはsample関数で同じように実装できます。カテゴリカル分布を使ってより一般的なGMMを実装するときにはsample関数を使用したほうが良いかと思います)。正規分布を選ぶ確率はprobで設定しており、今回の例では片方の正規分布を選択する確率を0.35で設定してみました。
次に、GMMを数式で確認していき、もう少し深く理解していきましょう。
まず、個の正規分布の中から1つを選ぶためには、カテゴリカル分布を採用すると便利です。
カテゴリカル分布は
から
の間の整数
を返します。そして、その整数
が出る確率が
となります。
つまり、数式で書くと以下の通りになります。
そして、選ばれた番目の正規分布の確率密度関数を以下のように定義します。
目標は得られたデータの確率分布
になりますので、
番目の正規分布の確率密度関数を用いて表すと以下のようになります。
これがGMMの式になります。各正規分布に対して重みをかけて足し合わせている形になります。
まとめ
今回はGMMについて紹介してきました。パラメータは得られている前提での紹介にとどまりましたが、次回はGMMのパラメータが定まっていない状態で、その推定を行う方法であるEMアルゴリズムについて紹介していきます。